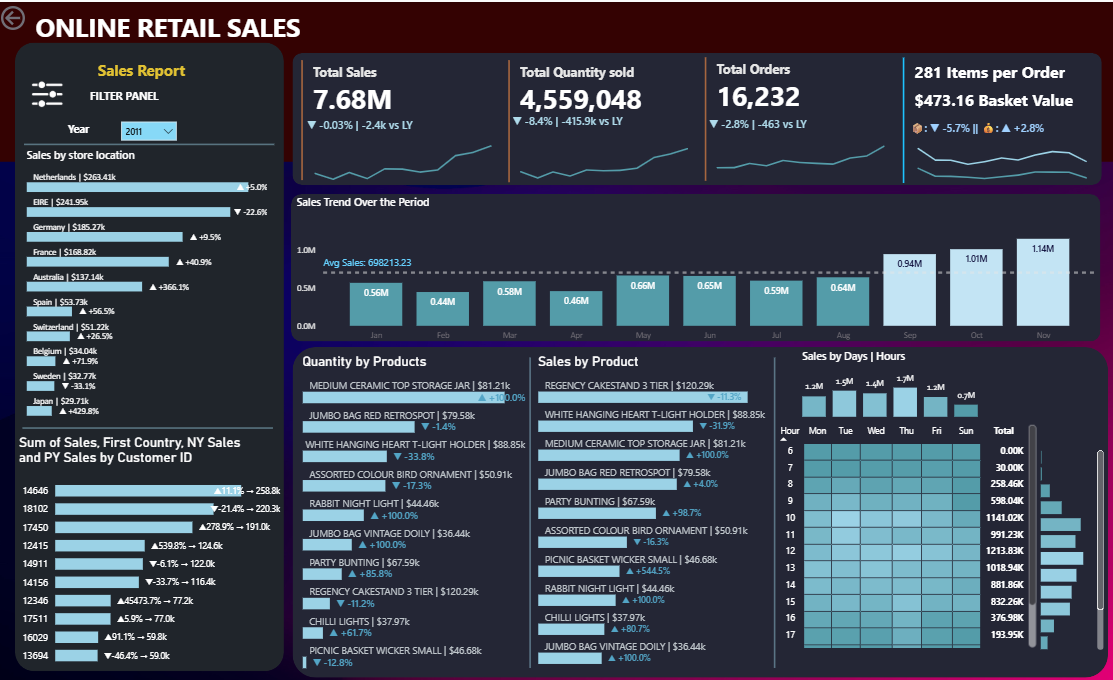
Core KPIs:
Total Sales = SUM(retail_data_cleaned[Sales])
Total Orders = DISTINCTCOUNT(retail_data_cleaned[Invoice])
Total Quantity sold = SUM(retail_data_cleaned[Quantity])
Avg Basket Value = DIVIDE([Total Sales],[Total Orders])
Avg Items per Order = DIVIDE([Total Quantity sold],[Total Orders])
CY / PY / NY measures:
CY Sales = CALCULATE([Total Sales], VALUES('Date Table'[Year]))
PY Sales = CALCULATE([CY Sales], DATEADD('Date Table'[Date], -1, YEAR))
NY Sales = CALCULATE([CY Sales], DATEADD('Date Table'[Date], +1, YEAR))
CY Order = CALCULATE([Total Orders], VALUES('Date Table'[Year]))
PY Order = CALCULATE([CY Order], DATEADD('Date Table'[Date], -1, YEAR))
CY Quantity = CALCULATE([Total Quantity sold], VALUES('Date Table'[Year]))
PY Quantity = CALCULATE([CY Quantity], DATEADD('Date Table'[Date], -1, YEAR))
Problem:
The dataset ends on December 9, 2011, making December 2011 incomplete. Comparing partial December 2011
to full December 2010 would lead to artificially low YoY metrics and misleading KPIs.
Solution:
1. Page Filter: A filter was applied on the "Sales Trend Over the Period" page to
exclude December:
Date Table[Date].[Month] → "is not December"
2. Measure Adjustment: The original CY measures used ALL('Date Table')
which removed the month filter context. They were updated to use
VALUES('Date Table'[Year]) to preserve the year context while respecting the month
filter.
Original CY Sales Measure (Problematic):
CY Sales =
VAR _Year = SELECTEDVALUE('Date Table'[Year])
RETURN
CALCULATE(
[Total Sales],
FILTER(
ALL('Date Table'),
'Date Table'[Year] = _Year
)
)
Revised CY Sales Measure (Corrected):
CY Sales =
CALCULATE(
[Total Sales],
VALUES('Date Table'[Year])
)
The same adjustment was applied to:
CY QuantityCY Orders- And any other CY metrics used for YoY comparison.
Result:
All YoY comparisons now accurately reflect January–November data for both years, avoiding biased
results due to incomplete December data.
Average & trend helpers:
Yearly Month Avg Sales = AVERAGEX(SUMMARIZE(ALLSELECTED('Date Table'), 'Date Table'[Month]), [Total Sales])
Daily Avg Sales = AVERAGEX(ALLSELECTED(retail_data_cleaned[InvoiceDate]), [Total Sales])
Color rules:
Color For columns = IF([Total Sales] > [Yearly Month Avg Sales], "Above Average", "Below Average")
Color For Daily Bars = IF([Total Sales] > [Daily Avg Sales], "Above Average", "Below Average")
CM/PM for MOM:
CM Sales = VAR selected_month = SELECTEDVALUE('Date Table'[Month])
RETURN TOTALMTD(CALCULATE([Total Sales], 'Date Table'[Month] = selected_month), 'Date Table'[Date])
PM Sales = CALCULATE([CM Sales], DATEADD('Date Table'[Date], -1, MONTH))
MOM Growth & Diff Sales =
VAR month_diff = [CM Sales] - [PM Sales]
VAR mom = DIVIDE(month_diff, [PM Sales])
VAR sign = IF(month_diff > 0, "+", "")
VAR sign_trend = IF(month_diff > 0, "▲", "▼")
RETURN
IF(
ISBLANK([PM Sales]) || [PM Sales] = 0,
FORMAT(month_diff / 1000, "0.0k") & " vs LM",
sign_trend & " " & sign & FORMAT(mom, "0.0%") & " | " & sign & FORMAT(month_diff / 1000, "0.0k") & " vs LM"
)
YOY & labeling:
YOY Growth & Diff Sales =
VAR year_diff = [CY Sales] - [PY Sales]
VAR yoy = DIVIDE(year_diff, [PY Sales])
VAR _sign = IF(year_diff > 0, "+", "")
VAR _sign_trend = IF(year_diff > 0, "▲", "▼")
RETURN
IF(
ISBLANK([PY Sales]) || [PY Sales] = 0,
FORMAT(year_diff / 1000, "0.0k") & " vs LY",
_sign_trend & " " & _sign & FORMAT(yoy, "#0.00%" & " | " & _sign & FORMAT(year_diff / 1000, "0.0k")) & " vs LY"
)
Label for Product Type (Sales) =
VAR MostCommonDescription = MAXX(TOPN(1, VALUES(retail_data_cleaned[Description]), COUNTROWS(retail_data_cleaned), DESC), retail_data_cleaned[Description])
RETURN MostCommonDescription & " | " & FORMAT([Total Sales]/1000, "$0.00k")
Label for Store Location = SELECTEDVALUE(retail_data_cleaned[Country]) & " | " & FORMAT([Total Sales]/1000, "$0.00k")
PlaceHolder = 0
Items per Order Label = FORMAT(DIVIDE([Total Quantity Sold], [Total Orders]), "0") & " Items per Order"